검색결과 리스트
분류 전체보기에 해당되는 글 83건
- 2012.12.04 page mapping
- 2012.11.14 정리해야 될것들
- 2012.09.11 mosfet 기호
- 2012.08.08 엑셀로 피팅
- 2012.08.03 SBD
- 2012.08.03 오프컬렉터
- 2012.07.27 labview
- 2012.07.27 matlab interp 2
- 2012.06.22 아ㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏ
- 2012.05.05 2012/5/5
글
page mapping
1. Page Mapping 그림 1. Page address re-mapping for page 그림 3 The overall architecture of the LAST scheme 출처 : http://matia.tistory.com/49
Page-Level Mapping 은 가장 기초적인 FTL 중 하나이다. Page-Level Mapping[1] 기법은 page의 모든 사상 정보를 사상 테이블에 저장하여 관리한다. 따라서 logical page를 어느 physical page에나 사상 할 수 있어, Block mapping에 비해 더 유연하게 mapping 정보를 관리할 수 있고 random small write에 대한 성능이 우수하다. 하지만 사상 테이블의 크기가 커져 이를 저장하기 위해서는 많은 메모리를 필요로 하는 단점이 있다. 그림 1은 Page-level mapping에서 Mapping table의 정보를 관리하는 모습을 보여준다. Physical Block내에 존재하는 특정 페이지에 대해 페이지 업데이트 요청이 들어왔을 때 해당 페이지를 순서에 상관없이 비어있는 다른 공간에 저장하고 저장된 위치의 physical address를 Mapping table에 저장함으로써 Logical page address와 Physical page address를 re-mapping한다. 이후 업데이트전의 페이지 정보는 불필요하게 된다(invalid).
2. Hybrid Mapping
Hybrid Mapping은 Page-Level Mapping 과 Block-Level Mapping의 장점만을 모아 필요에 따라 페이지 단위로 또는 블럭 단위로 데이터 처리를 한다. 그 구분은 일반적으로 요청된 데이터가 Sequential 로 나열된 것인지 아니면 Random 으로 나열된 데이터를 처리 하는 것인지에 따라 나뉜다. 다음 절에서는 각 FTL의 구동 방식에 대해 간단히 소개한다.
2.1. FAST
BAST에서는 페이지 업데이트가 발생하면 로그블록을 할당하여 out-of-place로 write 명령을 수행하는데, 로그블록과 데이터 블록은 1:1로 대응 되기 때문에 잦은 random write 발생시 로그 블록의 활용도가 떨어지고 블록 스레싱 현상이 발생할 수 있다.
그림2에서 보이듯이 FAST 로그블록과 데이터블록의 연관관계를 1:N으로 확장하여, 로그 블록에 더 이상 빈 공간이 없을 때 garbage collection을 실행하도록 하여 블록 스레싱 문제를 효율적으로 해결하고 Full merge의 비율을 줄일 수 있다. 또한 하나의 로그블록을 따로 관리하는데 이는 sequential write를 처리하기 위한 sequential 로그 블록이다. 하지만 FAST는 multiple task에 의한 multiple sequential write stream과 random write와 sequential write 명령이 혼합되어 들어오는 경우에는 효율적으로 처리하지 못한다.
2.2. LAST
그림 3에서 보이듯이 LAST도 FAST와 같이 로그블록을 sequential 로그블록과 random 로그블록으로 나눈다. Threshold 값을 기준으로 데이터의 크기에 따라 sequential write와 random write를 구분하여 두 명령이 혼합되어 들어오는 경우에도 효율적으로 처리할 수 있다. Random 로그 블록은 hot, cold 파티션으로 나누는데 해당페이지가 처음 random 로그 블록에 기록되는 경우 cold 파티션에 기록한 뒤, index k value을 두어 k value이내에 해당 페이지가 업데이트 되는 경우 hot 파티션에 기록한다. 자주 업데이트 되는 페이지를 hot 파티션에 모아둠으로써 merge operation의 횟수를 줄여 garbage collection의 효율을 얻을 수 있다. 또한 hot 파티션내의 특정 페이지들이 빈번하게 업데이트되어 하나의 블록이 모두 invalid 해지면(dead block) 한번의 erase operation만으로 로그 블록을 비울 수 있다.



'Learning stuff' 카테고리의 다른 글
| labview_2 (0) | 2012.12.11 |
|---|---|
| mearly machine diagram (0) | 2012.12.11 |
| mosfet 기호 (0) | 2012.09.11 |
| 엑셀로 피팅 (0) | 2012.08.08 |
| SBD (0) | 2012.08.03 |
설정
트랙백
댓글
글
정리해야 될것들
+ matlab
-기본 기능들@
-코드 분석@
classdef, logical func@
+ labview 자료 올리기@
+ verilog
- finite state machine@
- blocking, non-blocking@
+ review 했던것들
+ 논문 정리해서 올리기
설정
트랙백
댓글
글
mosfet 기호
부끄럽지만 이거 나 매일 헷깔려....
기호 말이야 기호ㅋㅋㅋ
N 형이 들어오는거고 P형이 나가는거야 그래
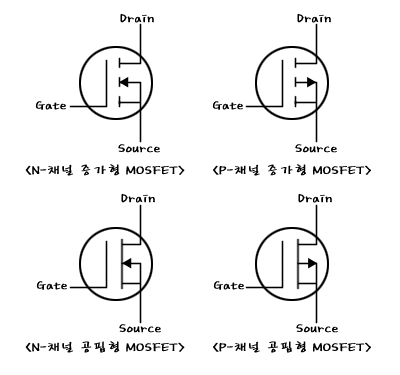
화살표는 N 형이면 전자 P 형이면 정공 이라고 보면 된다 즉
N형이면 +걸때 Drain 에서 source로 전류가 흐르고
P 형이면 -걸때 Source 에서 drain 으로 전류가 흐르고.....
'Learning stuff' 카테고리의 다른 글
| mearly machine diagram (0) | 2012.12.11 |
|---|---|
| page mapping (0) | 2012.12.04 |
| 엑셀로 피팅 (0) | 2012.08.08 |
| SBD (0) | 2012.08.03 |
| 오프컬렉터 (0) | 2012.08.03 |
설정
트랙백
댓글
글
엑셀로 피팅

'Learning stuff' 카테고리의 다른 글
| page mapping (0) | 2012.12.04 |
|---|---|
| mosfet 기호 (0) | 2012.09.11 |
| SBD (0) | 2012.08.03 |
| 오프컬렉터 (0) | 2012.08.03 |
| labview (0) | 2012.07.27 |
설정
트랙백
댓글
글
SBD
SBD에는 일반 다이오드와는 크게 다른 점이 있습니다. 일반적인 다이오드는 P형과 N형 반도체의 접합(PN접합)으로 되어 있습니다만, SBD는 금속과 반도체의 접합으로 되어 있습니다.
특성적으로는 PN접합과 유사한 정류 특성을 나타냅니다만, 내부를 들여다보면 큰 차이가 있습니다. PN 접합의 다이오드는 다수 캐리어와 소수캐리어에 의해 전하가 옮겨집니다만, SBD는 다수캐리어 밖에 없습니다. 이 때문에 매우 고속의 동작이 가능한 관계로, 고주파 영역에서 사용하기 좋다고들 하지요.
SBD의 눈에 띄이는 또한가지 특성 중 하나는, 역방향 전압과 순방향 전압이 낮다는 것입니다. 역방향 전압은 일반 PN 접합 다이오드보다 1자리수 정도 낮고, 순방향 전압은 상대적으로 반정도밖에 되지 않습니다.
<그림 9-1>에 고주파에서의 SBD 등가회로를 나타내었습니다. 직렬저항 Rs, 비선형 접합저항 Rj, 비선형 접합 캐패시턴스 Cj로 구성되어 있습니다. SBD를 검파회로와 믹서에 사용할 때는 Rs와 Cj가 작은게 좋습니다.
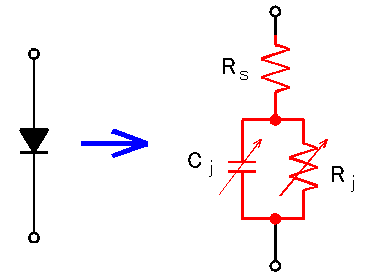
<그림 9-1> 쇼트키 배리어 다이오드 (SBD) 등가회로
'Learning stuff' 카테고리의 다른 글
| mosfet 기호 (0) | 2012.09.11 |
|---|---|
| 엑셀로 피팅 (0) | 2012.08.08 |
| 오프컬렉터 (0) | 2012.08.03 |
| labview (0) | 2012.07.27 |
| matlab interp (2) | 2012.07.27 |
설정
트랙백
댓글
글
오프컬렉터
오픈 컬렉터(open collector) 출력의 장단점
저번시간에 이어 오픈컬렉터에 대해 알아보겠습니다.
먼저 오픈컬렉터는 트랜지스터의 컬렉터가 오픈된 채로 출력 핀으로 나와 있기 때문에
오픈 컬렉터 출력이라고 했는데요 그럼 오픈컬렉터를 사용하는 이유는 무엇일까요?
토템폴 출력에서 출력단을 구성하는 두 스위치가 동시에 ON 상태에 있어서는 안됩니다.
아래 그림을 예로 보자면

왼쪽 소자의 논리 ‘1’ 출력과 오른쪽 소자는 논리 ‘0’ 출력을 서로 연결하면 왼쪽 소자의 VDD에서
오른쪽 소자의 GND까지 전류가 흐르게 됩니다.
결과적으로 과전류가 흐르기 때문에 이런 상태가 지속되면 소자가 파괴되겠죠.

오픈컬렉터의 경우 소자 A의 Q2가 [OFF] 소자 B의 Q2가 [ON] 상태로 두 출력을 서로 연결하여도
오픈 컬렉터 소자는 회로에서 분리된 상태로 회로의 다른 부분에 아무런 영향을 미치지 않게 됩니다.
요약하자면 오픈 컬렉터 출력을 서로 묶으면 개별 소자의 출력 중 단 하나라도 논리 ‘0’을 출력하면
전체 출력은 논리 ‘0’이 되고 개별 소자의 출력이 모두 논리 ‘1’일 때에만 전체 출력이 ‘1’이 됩니다.
이것은 각 개별 소자의 출력을 AND 게이트로 연결한 것과 논리적으로 같은 결과이므로
이렇게 오픈 드레인 출력을 모두 묶은 구조를 선으로 연결한 AND라는 뜻으로
와이어드 AND (wired AND) 연결이라고 부르죠.
오픈컬렉터의 장점
1.확장성이 뛰어난 와이어드 AND 연결이다.
2.소자의 동작 전원 전압과 다른 전압을 출력할 수 있다.
단점
1.토템폴 소자에 비해 속도가 느리다.
2.풀업 저항으로 인해 전력 소비가 발생한다.
'Learning stuff' 카테고리의 다른 글
| 엑셀로 피팅 (0) | 2012.08.08 |
|---|---|
| SBD (0) | 2012.08.03 |
| labview (0) | 2012.07.27 |
| matlab interp (2) | 2012.07.27 |
| Converters (0) | 2012.04.12 |
설정
트랙백
댓글
글
labview
다까먹음 ㅋㅋ 그게 중요함 ㅋㅋ
여튼 뭐 많이 캡쳐해났는데 설명하기는 귀찮고 그냥 파씽해야지






에라이 잘 보이지도 않네 ㅋㅋ
이것들은 한번 시험삼아서 내가 생각하고 있는 이 컨셉이 맞나 싶어서 만들어 본 것 들이다.
참고로 프로그램이 커지면 랩뷰는 불편하다 아주 ㅠ 선이많아서....
여튼 글로 쫌 적어나야지
1. while loop 의 원리는 똑같다. 근데 특이한 점이 while 문에 equal 5 할때 끝나게 해놓으면 5일때도 실행하고 끝난다 즉 while(x!=5)했는데 5일때도 실행하고 끝난다. while 보다는 while do 같다. 실행하고 조건검사 하는듯. 그리고 while 문 안에 읽고 싶은 값이 있어야 계속 scan이 가능하다. 무슨말인지 모르겠지만 아주 당연한 소리이다. 예를 들어 내가 죽어라 썼던 PLZ334WL에서 Voltage 값을 읽어오고 싶다( 물론 active load 지만...) 여튼 이러면 while 문 안에 그게 있어야지 계속 값을 스캔 해 온다. 그리고 while 문이 끝나야 그 값이 밖으로 뿅 나간다. 이것도 무슨 소리인지 모르겠지?? 예를들어 PLZ334WL 에서 Voltage 값을 읽어오는 선이 중간에 while 문 루프를 지나가고 indicator 로 간다고 치자.. 그러면 while 문이 끝날때 까지는 읽어온 그 값은 indicator 에 가지 않는다. 즉, while(); 효과가 난다는 말이다.
2. case를 써서 step을 만들것(case의 1,2,3,4 를 조건에 따라 변경시키고 그 조건은 또한 조건(if==case)을 써서 변화 시킴)
가장 기본적인 구조 같은데 while 문을 집어넣고 그 만에 case 문을 넣어서 step을 변경해 가면서 실행한다. 그리고 while 문에 shift register를 추가시키고 1을 증가시키면서 어떠한 조건이 되면 while 문이 끝나게 한다. 그리고 필요하다면 flat sequence 구조도 적절하게 잘 사용해 주면 좋다! 사실 이게 다다...ㅋㅋㅋ
3. while 문이 두개가 있다고 가정하고 안에의 while문이 계속 돌고있다고 가정할때 두개의 while 문 밖에서 값을 변화 시켜도 그 변경된 값이 안에서는 update 되지 않는다.
4. 모든 while 문은 parallel 하게 돌아간다.
5. 파일 저장에서 path 가 바뀌게 되면 바로 그파일 write 를 중지하고 변경된 path 에 맞는 장소에 저장을 시작한다.
6. 여러 디바이스를 한꺼번에 많이 실행하면 timeout error 가 난다. 그러니까 flat sequence를 써서 따로따로 실행하게 단계를 나누어주셈.
7. 랩뷰는 멍청하다
8. end of line 이 아니라 carriage return constant 가 엔터다.
9. close vi 를 따로 만들어서 session close 를 처리 해 준다. 이건 어떻게 이벤트 처리를 하면 될것 같기도 한데.... 몰라 ㅋㅋ
10. 배열(array)의 행과 열은 0부터 시작한다.
마지막으로 finally 만든 vi
한장에 안담기니까 일부분만 김치

'Learning stuff' 카테고리의 다른 글
| SBD (0) | 2012.08.03 |
|---|---|
| 오프컬렉터 (0) | 2012.08.03 |
| matlab interp (2) | 2012.07.27 |
| Converters (0) | 2012.04.12 |
| OP AMP의 기본동작 (1) | 2012.04.11 |
설정
트랙백
댓글
글
matlab interp
요즘은 그래도 쫌 널널하니까 야아깐
최근 가장많이 한게 labview 와 matlab 이다.
가장 헷깔리는걸 기록하자면
matlab에서 좌표는

요거란 거다
meshgrid를 쓰면 저거의 반대지만
이경우를 제외한 나머지는 저런듯.....
그래서 [y,x,z]=meshgrid(y,x,z) 이렇게 적거나
귀찮으면 [x,y,z]=ndgrid(x,y,z) 이렇게 하여 mesh form의 grid를 형성해 준다.
난 주로 curve fitting 의 용도로 interp3, inter2, inter1 을 사용하였는데
이상한 오류가 나는 바람에 딴걸 알아보다 보니까.. 응 더 좋은걸 오늘 알게 되었다.
그 두개가 triscatteredinterp 와 griddata 다 griddata 얘는 griddata3로 하면 3D도 되네?? 근데 뭐 어쩄든 얘들 좋은점이 Non uniformly spaced sample들로 fitting 할수 있다는거
근데 griddata 얘는 쓰기 싫은게 linear 하고 nearest 밖에 안되여.... triscatteredinterp 는 fitting 된 function을 생성해주고 얘는 보니까 column vector 형태로 in 을 넣어죠야 되더라..... 자세한건 검색요........
Create a data set:
x = rand(100,1)*4-2; y = rand(100,1)*4-2; z = x.*exp(-x.^2-y.^2);
Construct the interpolant:
F = TriScatteredInterp(x,y,z);
Evaluate the interpolant at the locations (qx, qy). The corresponding value at these locations is qz .
ti = -2:.25:2; [qx,qy] = meshgrid(ti,ti); qz = F(qx,qy); mesh(qx,qy,qz);
Data gridding and hypersurface fitting for 3-D data
Syntax
Description
w = griddata3(x, y, z, v, xi, yi, zi) fits a hypersurface of the form  to the data in the (usually) nonuniformly spaced vectors (
to the data in the (usually) nonuniformly spaced vectors (x, y, z, v). griddata3 interpolates this hypersurface at the points specified by (xi,yi,zi) to produce w. w is the same size as xi, yi, and zi.
Examples
Example 1
Interpolate the peaks function over a finer grid.
[X,Y] = meshgrid(-3:.25:3); Z = peaks(X,Y); [XI,YI] = meshgrid(-3:.125:3); ZI = interp2(X,Y,Z,XI,YI); mesh(X,Y,Z), hold, mesh(XI,YI,ZI+15)
Examples
To generate a coarse approximation of flow and interpolate over a finer mesh:
[x,y,z,v] = flow(10); [xi,yi,zi] = meshgrid(.1:.25:10, -3:.25:3, -3:.25:3); vi = interp3(x,y,z,v,xi,yi,zi); % vi is 25-by-40-by-25slice(xi,yi,zi,vi,[6 9.5],2,[-2 .2]), shading flat
참고로... extrapolation은 spline 밖에 안되더라 그래
마지막으로 몇개의 데이터로 3D Interpolation 한 결과 ㅋㅋ

나중에 보면 기억날진 모르지만 스토리는 대략
1. Vin 별 데이터를 받아서 downsample 을 Vout 방향으로 0.5 간격으로 해주어서 자료를 줄인후에 나온 자료들 가지고 interp3 하거나
2. 저 위에껀 있는 그래프의 결과인... 그래 일단 측정한 자료의 값들을 column vector로 쫙 뽑아내서 triscatteredinterp 를 통과시켜주어서 함수를 뽑아낸 다음 그린다!
간단하네 뭐.. ㅋㅋ
'Learning stuff' 카테고리의 다른 글
| 오프컬렉터 (0) | 2012.08.03 |
|---|---|
| labview (0) | 2012.07.27 |
| Converters (0) | 2012.04.12 |
| OP AMP의 기본동작 (1) | 2012.04.11 |
| Open collector, Open drain (0) | 2012.04.11 |
설정
트랙백
댓글
글
글
2012/5/5
ㅋㅋㅋ 셤이다 뭐다해서 바쁘다보니
업뎃을 잘 못하네;;
그래도 정리 해논게 있으니 공부하면서 차례로 업뎃 해야지
근데 요즘 느끼는건
진짜 일하기에 바빠서 공부할 시간이 없다는거다 ㅠ
가만히 하고 있으면 진짜 가끔
'아..... 공부 하고 싶다' 는 미친 생각도 든다 ㅋㅋ
여튼 오늘 느낀것 중 가장 큰것은 Power supply 의 current, voltage 는 실제값이 아닌 limit 값이다.
for example, super cap에 물려있고 거기 5v 가 걸려있으면 actual volatage 칸에 5라고 뜸(단, OVP 가 아닐떄ㅇㅇ)
뭐이래 간단한것도 몰라 ㅡㅡ
PS.
아참 그사이에 차지 보드 4개 + 이것저것 잡다고리 한거 납땜 엄청해서
납땜에는 어느정도 속도가 붙는듯 ㅋㅋ
'Everyday' 카테고리의 다른 글
| 요 (0) | 2013.03.15 |
|---|---|
| 아ㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏ (0) | 2012.06.22 |
| 외할아버지 상 당하시다 (0) | 2012.02.20 |
| 2012_2_20 (0) | 2012.02.20 |
| 2012_2_7 (0) | 2012.02.07 |
